
LangChain + RAG 实践
前置准备
- gpt 账号
- python3.11 以及相关依赖
LangChain 框架基础知识
LangChain Docs:
整体框架

- LangChain-Core:基础抽象和 LangChain 表达式语言
- LangChain-community:第三方集成
- LangChain:构建应用程序认知架构的链、代理和检索策略
Components
LangChain 为各种组件提供了标准的、可扩展的接口和外部集成,这些组件对 llm 的构建非常有用。有些组件是由 LangChain 实现的,有些组件是依靠第三方集成来实现的,还有一些则是混合的。
后面的实际应用会根据实际需要,组合使用这些组件。
1. Chat models
使用消息序列作为输入并返回聊天消息作为输出的语言模型,Chat Model 支持为对话消息分配不同的角色,帮助区分来自 AI、用户和指令的消息。 尽管底层模型是消息输入和消息输出,但 LangChain 包装器还允许这些模型接受字符串作为输入(会被转化为 HUmanMessage)。这意味着我们也可以使用聊天模型来代替 llm。
标准参数:
model: the name of the modeltemperature: the sampling temperature (0-1 数值越大 结果随机性越强)timeout: request timeoutmax_tokens: max tokens to generatestop: default stop sequencesmax_retries: max number of times to retry requestsapi_key: API key for the model providerbase_url: endpoint to send requests to
对于多模态的支持:https://python.langchain.com/v0.2/docs/integrations/chat/#advanced-features
一些应用:
2. LLMs
纯文本格式的模型,目前已经可以用 Chat Model 代替
3. Message
根据角色可以分为 HumanMessage、AIMessage、SystemMessage、ToolMessage、FunctionMessage
3.1 HumanMessage
代表用户发出的消息,字符串会被作为 HumanMessage
3.2 AIMessage
代表是大模型发出的消息,通常会额外包含 reponse_metadata 和 tool_calls 信息
3.3 SystemMessage
代表系统消息,告诉模型该如何做。不是所有模型支持(GPT 支持)
3.4 ToolMessage
代表工具调用返回的接口
3.5 FunctionMessage(todo)
- 这是一个遗留消息类型,对应于 OpenAI 的遗留函数调用 API。应该使用 ToolMessage 来对应更新后的工具调用 API。 这表示函数调用的结果。除了角色和内容之外,该消息还有一个 name 参数,该参数表示为产生此结果而调用的函数的名称。
4. Prompt templates
提示模板将用户输入和参数转换为语言模型的指令,用于指导模型的响应,帮助它理解上下文并生成相关和一致的基于语言的输出。 提示模板接受一个字典作为输入,其中每个键代表提示模板中要填写的一个变量。 提示模板输出一个 PromptValue。这个 PromptValue 可以传递给 LLM 或 ChatModel,也可以强制转换为字符串或消息列表。
常见的提示词模板类型:
4.1 String Prompt Templates
最简单的提示词模板,用于一些很简单的任务。
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("Tell me a joke about {topic}")
prompt_template.invoke({"topic": "cats"})4.2 Chat Prompt Templates
用于格式化消息列表,而且可以为每条消息设定不同的角色
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant"),
("user", "Tell me a joke about {topic}")
])
prompt_template.invoke({"topic": "cats"})4.3 Messages Placeholder
Chat Prompt Templates 的消息列表是固定的,如果希望支持用户能够传递一个消息列表,将这些消息放入特定的位置,需要使用 MessagesPlaceholder 的方法。
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant"),
MessagesPlaceholder("msgs")
])
prompt_template.invoke({"msgs": [HumanMessage(content="hi!")]})5. Output parsers
这里是指将模型的输出解析为结构化格式。现在越来越多的模型支持函数(或工具)调用,它可以自动处理这个问题,建议使用函数/工具调用而不是这种方式。
具体支持的转化格式可以参考手册,常见格式有 JSON、XML、CSV 等等
Chat history
大多数 LLM 应用程序都有会话接口。对话的一个重要组成部分是能够引用对话之前介绍的信息。
Chath history 是 LangChain 一个类,它可以用来包装任意链,跟踪 chain 的输入和输出,并将它们作为消息附加到消息数据库中。在后续的交互中加载这些消息并将它们作为一部分输入传递到 chain
Documents Loaders
LangChain 支持加载 PDF、BiliBili、CSV 等上百个数据源类型,封装为 xxxLoader 的方法调用
from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(
... # <-- Integration specific parameters here
)
data = loader.load()Text splitters
将长文档拆分成更小的块,有助于适合模型的上下文窗口,得到更好的效果。具体的分块策略根据不同的应用场景也会有所区别,需要尝试。
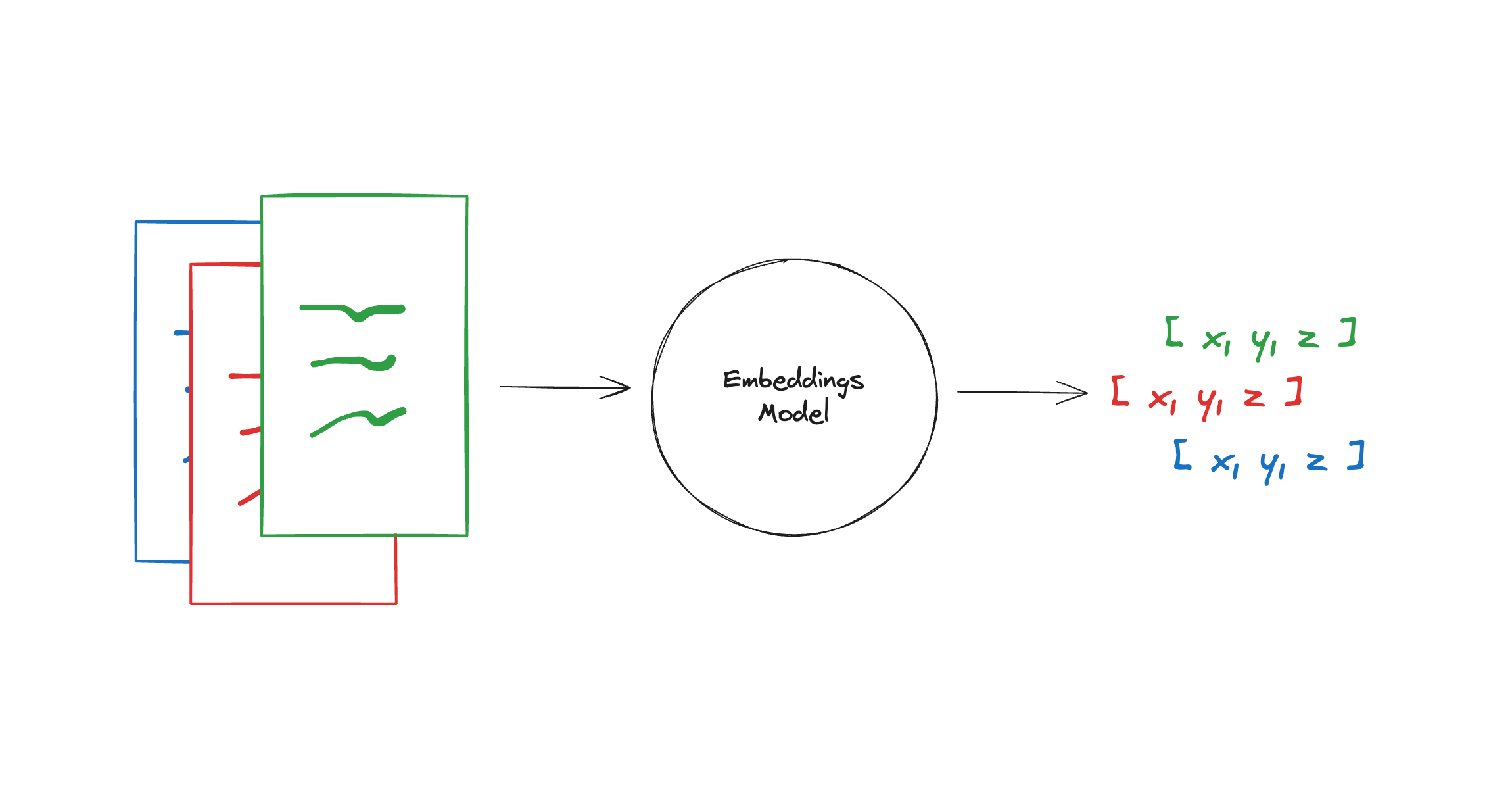
Embedding models
在 RAG 等应用场景,我们需要将资料通过适合的 embedding 模型转化为矢量,并存入向量数据库中,以便后续更高效精准的检索。
Vector stores
主要用于存储上面步骤转化的数据,以及后面的检索。常见的矢量数据库有 Chroma、Milvus、Pinecone、ES 等
Retrievers
检索器可以从矢量数据库、各种文档中检索匹配度 topk 的条目并以 Document 格式返回
Tools
Tools 被设计为由模型调用的实用程序:其输入由模型生成,输出会传递回模型。
使用场景:需要一个模型来控制部分代码或调用外部 api
A tool consists of:
- The name of the tool.
- A description of what the tool does.
- A JSON schema defining the inputs to the tool.
- A function (and, optionally, an async variant of the function).
当工具绑定到模型时,名称、描述和 JSON 模式将作为模型的上下文提供。给定一组工具和一组指令,模型可以请求调用具有特定输入的一个或多个工具。典型用法如下:
tools = [...] # Define a list of tools
llm_with_tools = llm.bind_tools(tools)
ai_msg = llm_with_tools.invoke("do xyz...") # AIMessage(tool_calls=[ToolCall(...), ...], ...)Agents
语言模型本身只能输出文本 不能执行操作。代理使用 LLM 作为推理引擎来确定采取哪些操作以及这些操作的输入应该是什么。这些操作的结果可以反馈给代理,由代理决定是否需要更多的操作,或者是否可以完成。
Agent 是真正能在实际场景中帮助到我们的工具之一,十分重要。LangGraph是专门用于创建高度灵活且功能强大的 Agent 框架,后面专门学下。
CallBacks
类似于钩子函数,支持在对应的事件触发执行自定义的 handler,可以用例打日志、监控等任务。
RAG
检索增强生成技术可以让大模型生成的答案更加符合我们的需求,相比于微调大模型成本也会更低,因此是当前热点之一。
0. 工作流程
这篇文章很适合作为 RAG 入门,清晰简单地介绍了 RAG 理论知识、主体流程和 LangChain 实践。引用下其中的工作流程
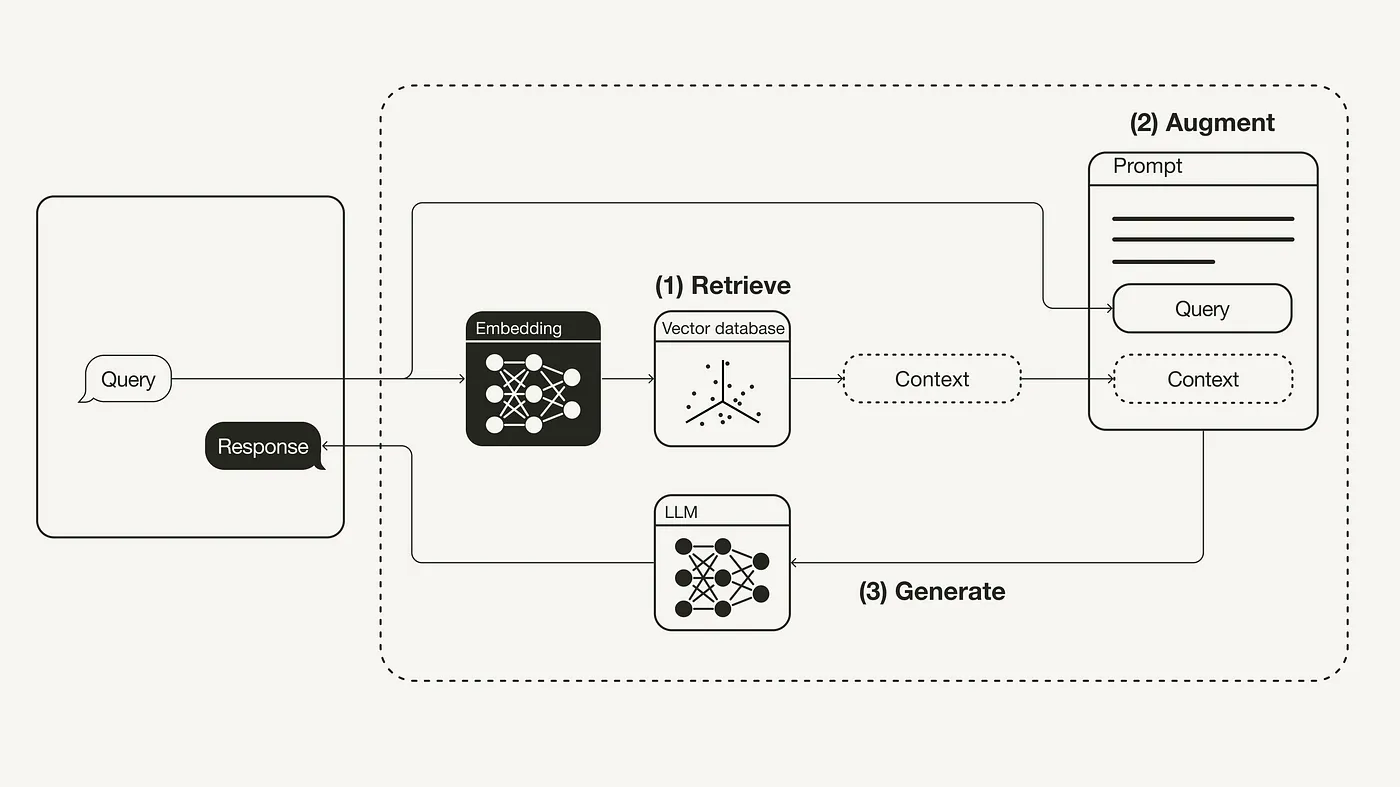
0-1. 准备环节-训练知识库
这个环节是将我们内部非结构化的资料(可以是 PDF 文档、网页等)转化为向量并存储在向量数据库中。这通常包含下面步骤:
- 收集数据并将其加载
- 文档分块处理
- 对内容 embedding
- 存储到向量库
0-2. 检索 Retrieval
retriever = vectorstore.as_retriever()0-3. 增强 Augmented
这里的增强主要是提示词增强,不仅仅包含原 query,还包含了通过检索查到的知识库文档片段。下面是一个知识库问答的 demo
from langchain.prompts import ChatPromptTemplate
template = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)
print(prompt)0-4. 生成 Generation
这里的生成与正常 LLM 输出没有很大差别。
1. RAG 的技术点
1-1 数据索引:数据集清洗
//TODO
1-2 数据索引:Chunking
1-3 数据索引:Embedding
//DOING
1-4 检索优化:Rerank 重排序
//DOING
在拿到检索结果后,还可以使用 rerank 对结果重新排序,以达到更优的查询效果。
1-5 生成:提示词优化
//DOING
2. 应用场景
- 业务机器人:快速查询内部手册
- 根据需求文档生成具有领域知识的测试用例